工場における異常検知の手法とAI活用のデメリット
かんたんデジタル現場帳票「tebiki現場分析」およびかんたん動画マニュアル作成ツール「tebiki現場教育」を展開する、現場改善ラボ編集部です。
製造業の現場では、設備の故障や品質トラブルを未然に防ぎ、生産性と安全性を高めるための「異常検知」は近年、AI(人工知能)による自動検知へと進展しています。
しかしAIを活用した異常検知にはいくつかのデメリットや課題もあり、一筋縄で現場改善は進みません。
この記事では、工場における異常検知の定義と重要性を皮切りに、異常検知の主な手法、そしてAI活用のメリット・デメリットを整理しながら、どのようにすれば「迅速かつ正確な異常検知」を実現できるのかを、企業事例を交えながら解説します。
「迅速かつ正確な異常検知」を実現する上で、AI導入の前に、まず取り組むべきは日々の「異常の兆候」を記録する現場の帳票運用です。
※従来の紙の帳票は「作成」がゴールになりがちで、異常発見や対策が遅れがちです。一方で紙帳票の電子化(デジタル現場帳票)は、入力したデータが「瞬時に」グラフ化され、品質不良や設備トラブルを事前に予測し、回避できます。
ただいまデジタル現場帳票のデモ体験を実施中。紙帳票との違いをまずはご体感ください(下の画像をクリック)。
>>デジタル現場帳票のデモ画面を体験してみる
※フォーム入力後、その場でデモ画面に切り替わります
目次
工場における異常検知とは?その重要性と基本的な考え方
まずは異常検知について理解を深められるよう、以下の点に言及します。
- 異常検知の定義と目的
- 異常検知によって検知できる工場の「異常」の例
異常検知の定義と目的
異常検知とは、通常時に得られるデータや状態と比べて「明らかに異なる挙動」を検出する技術を指します。統計的な外れ値や、機械学習によって学習された正常パターンからの逸脱などを対象とし、「いつもと違う」を数値的に捉えるのが特徴です。
製造業における異常検知の主な目的は以下のとおりです。
- 設備の故障予防・停止の未然防止
- 品質不良の早期発見
- 熟練者の勘・経験の数値化
- 人的ミスの低減と作業効率の向上
設備の故障予防・停止の未然防止
異常検知は、突発的な設備トラブルを未然に防ぐ上で重要な役割を果たします。
設備トラブルの未然防止例として、株式会社日本電気化学工業所の取り組みが挙げられます。同社では、温度データのわずかな異常をリアルタイムで可視化したことで、配管の微細な穴を早期に発見し、ライン停止を回避しました。
このように、通常とは異なるパターンを即座に察知し、故障の前兆をとらえることで、生産ラインの中断リスクを最小限に抑えることが可能です。
ちなみに、製造業における設備トラブルは多くの現場で課題として取り上げられています。具体的に言うと、保全業務の多くが暗黙知となっており、属人化している現場が後を絶ちません。
「製造業の設備トラブルによる生産性低下を解消する設備保全のDX(pdf)」では、保全業務を形式知化して設備の異常を早期発見する術がまとめられているので、あわせて参考にしてみてください(下の画像をクリック)。

品質不良の早期発見
品質不良を初期段階で発見するためにも、異常検知は有効です。
デジタル化によって得られるリアルタイムデータを活用することで、例えば処理温度の変化といった製品品質につながるパラメータの微妙なズレを即座に把握できるからです。こうした異常が早期に発見できないと不良の発生に直結します。
したがって異常検知は、不良品の流出や歩留まりの低下といった問題の芽を早期に摘むことが可能で、顧客満足度の向上にもつながるでしょう。
関連記事:【改善事例あり】製造業における品質不良の原因と8つの対策
熟練者の勘・経験の数値化
熟練者の勘や経験を新人に伝えるには「技術の見える化」が必要ですが、異常検知の仕組みを導入することで、これまでベテランの経験に頼っていた判断基準を「定量的なデータ」として蓄積できます。
こちらも株式会社日本電気化学工業所の取り組み例が挙げられますが、同社は記録データのデジタル化とリアルタイム共有を推進したことで、現場の異常対応ノウハウが蓄積され、形式知として全社に共有できるようになりました。
熟練者の勘・経験の数値化によって、新人や非熟練者でも一定水準の対応が可能となり、技術伝承や作業標準化がスムーズに進むでしょう。
迅速な異常検知の体制整備に成功した、日本電気化学工業所の詳細な取り組み事例は以下のインタビュー記事からご覧いただけます。あわせて参考にしてみてください。
インタビュー記事:品質不良の未然防止をリアルタイムデータで実現。異常値検知を迅速にできた理由。
ヒューマンエラー(人為的ミス)の低減と作業効率の向上
異常検知の仕組みは、人の見逃しや判断ミスなどヒューマンエラーを補完する役割もあります。
例えば、温度や圧力といった重要な指標に対し、あらかじめ設定された閾値を超えた際に即座にアラートが上がることで、作業者が気づきにくい異常も確実に捉えることが可能です。結果として、点検や監視作業の負担が軽減され、作業のスピードと正確性の向上が期待できます。
また、異常の通知や記録が自動化されていれば、対応の漏れも防げ、管理者による確認作業も効率化できます。
製造業におけるヒューマンエラー対策は喫緊の課題となっていますが、現場の仕組みづくりによって一定の未然防止が可能です。その取り組みについてまとめられた資料「製造業におけるヒューマンエラーの未然防止と具体的な対策方法(pdf)」もあわせて参考にしてみてください(下の画像をクリック)。

異常検知によって検知できる工場の「異常」の例
工場における「異常」は一言で言っても多種多様です。ここでは、異常検知で検出可能な例を紹介します。
設備・機械の異常の例
設備・機械の異常として以下の4つの例があります。
- モーターの振動数の急激な変化
- ベアリング温度の異常上昇
- 異音の発生(例:軸ずれや摩耗)
- 油圧・電流・圧力の異常値
例えば、モーターの振動数が急変した場合は軸のずれや摩耗、内部破損といったトラブルがある可能性があります。ベアリング温度の上昇も同様に、潤滑不足や摩耗の兆候であり、放置すれば焼き付きや設備停止につながります。
また、異音の発生は機械内部の破損や緩みのサインであり、音を聞き逃すと突発的な故障や生産中断を招く恐れがあるので注意しましょう。油圧や電流、圧力の異常値も生産機器の制御不良を意味し、品質不良や設備損傷につながるため早期対応が必須です。
工程・作業プロセスの異常の例
工程・作業プロセスの異常として以下の4つの例が挙げられます。
- 成形機の射出圧の乱れ
- 溶接ラインの通電時間の異常
- 混合工程での材料比率のずれ
- 塗装ムラや厚み不足の発生
射出成形機の圧力乱れや通電時間の異常は、製品の充填不足・接合不良につながります。混合比率のずれは配合ミスによる製品不良を引き起こし、塗装ムラや膜厚不足は、顧客からのクレームや出荷後の不具合リスクを高めます。
製品品質の異常の例
製品品質の異常の例として以下の4つが挙げられます。
- 表面のキズ・打痕・バリ(画像による外観検査)
- 寸法公差外れ(3D計測やCAD比較)
- 色の違いや変色
- 異物の混入(異音・画像データで検出)
表面のキズやバリ、寸法のズレなどは見た目や機能性に影響します。とくに寸法公差を超えるズレは、組立時の不良や性能不具合の原因になります。
また色むら・変色・異物混入といった異常は、顧客の受け取り時にすぐに気づかれやすく、返品につながるので注意が必要です。
作業者の動作異常の2つの例
- 組立ラインでの部品取り付け漏れ
- サイクルタイムの著しいばらつき
部品の取り付け漏れやサイクルタイムの大幅なばらつきは、作業者のミスや不慣れを示すサインです。
こうしたサインを見逃すと、生産ラインにおける作業のリズムやペースが乱れ、後工程に影響を与える恐れがあります。また、長期的には技能習熟や作業標準の改善が進まない要因にもなります。
関連記事:タクトタイム・サイクルタイム・リードタイムの計算と改善方法【意味や違いも解説!】
工場における異常検知の主な手法
工場では、異常検知は従来の統計的な方法から、近年注目されるAIによる高精度な検知まで、数多くの手法があります。そこでここからは、「AI以外の異常検知」と「AIを活用した異常検知」それぞれの手法について紹介します。
よくある手法(AI以外)
AI以外のよくある手法として以下の4つの方法が挙げられます。
- ホテリング理論
- k近傍法(k-NN)
- ルールベース判定
- SPC(統計的工程管理)
AIを活用していない、異常検知の手法それぞれの概要やメリット、限界・課題について、以下の表にまとめています。
| 手法名 | 概要 | メリット | 限界・課題 |
|---|---|---|---|
| ホテリング理論 | 多変量正規分布を仮定し、平均からの距離で異常を判定 | シンプルで理論的裏付けあり | 分布前提が現場に合わないと誤検知が多い |
| k近傍法(k-NN) | 近傍データとの距離により異常度を計算 | 非線形なパターンにも対応可能 | パラメータ選定が難しく、計算負荷が高め |
| ルールベース判定 | 閾値や条件を事前に設定し異常を検知 | 実装が容易、理解しやすい | 閾値管理が煩雑、柔軟性が低い |
| SPC(統計的工程管理) | 管理図などを用いて工程の安定性を評価 | 製造業で実績多数、教育済み人材が多い | 突発的な異常への反応が遅れがち |
よくある手法(AI活用)
AIを活用した手法として、以下の4つが代表的です。
- 教師なし学習(Autoencoderなど)
- 教師あり学習(SVM・CNN等)
- 異常スコア予測(One-Class SVM等)
- AIによる画像・音声解析
AIを活用した異常検知の手法それぞれの概要やメリット、限界・課題について、以下の表にまとめています。
| 手法名 | 概要 | メリット | 限界・課題 |
|---|---|---|---|
| 教師なし学習(Autoencoder等) | 正常データを学習し、逸脱を異常として検知 | 異常データが少なくても運用可能 | 正常データの質が低いと誤検知リスク |
| 教師あり学習(SVM・CNN等) | 正常/異常ラベル付きで分類モデルを学習 | 学習精度が高く、精密な検知が可能 | 異常データの収集が必須で実用が難しい |
| 異常スコア予測(One-Class SVM等) | 正常クラスのみで境界を学習し逸脱を異常判定 | ラベル付け不要、汎用性あり | 境界の精度に依存しやすく調整が必要 |
| AIによる画像・音声解析 | 画像・音声などの非構造データを学習・識別 | 熟練者の目や耳をAIで再現可能 | データ収集・アノテーションのコストが大 |
製造業における、AIを活用した異常検知のメリットとデメリット
製造業におけるAIを活用した異常検知は、メリットがある一方で、デメリットや注意点も潜んでいます。
AIは単に導入すればいかなる状況でも異常の早期検出が可能になる、というわけではなく、あくまで自社や現場に沿った検知手法を検討することが重要です。
その判断材料として、ここからは異常検知のAI活用メリット・デメリットをそれぞれ解説します。
AI導入によるメリット
AI導入によるメリットとして以下の3点を解説します。
- 熟練者の暗黙知の形式知化支援
- 検知精度の向上(微細な変化、複雑なパターンの検知)
- 24時間監視、省人化
熟練者の暗黙知の形式知化支援
熟練作業者の「経験」や「勘」といった暗黙知は、長年の現場経験に裏打ちされた貴重な資産ですが、属人化しやすく継承が困難でした。AIを活用すれば、熟練者が下す判断をデータとして蓄積・学習し、その判断パターンをAIアルゴリズムとして構築することが可能です。
このように熟練者の暗黙知をAIに組み込むことで、そのノウハウがシステム内で一種の形式知として機能し、再利用可能になります。これにより技術伝承のハードルが下がり、経験の浅い作業員でもAIの支援を通じて、あたかも熟練者の知見を借りるかのように高度な判断を行えるようになります。
しかしながら、AIの判断に過度に依存する体制は避けるべきです。
AIを有効なツールとして活用し、異常検知の精度や効率を高めると同時に、経験の浅い作業員自身が「なぜAIがそのように判断したのか」を理解しようと努め、自ら異常を検知するための知識や経験を養う教育体制をあわせて整備することが、技術伝承につながる根本的な技術力向上と自律的な人材の育成に不可欠です。
関連記事:【事例あり】技術伝承が進まない根本課題と5つの具体策
検知精度の向上(微細な変化、複雑なパターンの検知)
AIは、人間には見逃されがちな微細な変化や、複雑なパターンを高精度で捉える力があります。従来のルールベースや閾値による手法では、あらかじめ定義された範囲外の異常を見落とす可能性がありましたが、AIは大量のデータから正常・異常の特徴を自動で学習し、予測精度を高められます。
特に、画像認識やセンサーデータの異常検知では、数値や形状のわずかな違いを的確に把握し、故障の予兆を早期に察知することが可能です。
関連記事:製造業の品質検査に潜む課題と改善策!検査員スキル向上事例も解説
24時間監視、省人化
AIを活用した異常検知システムは、休むことなく24時間365日監視を続けることが可能です。したがって夜間や休日の監視体制にかかっていた人員を他の業務に振り分けることが可能となり、省人化と業務効率化に寄与します。
また、人手による監視では見逃しやばらつきが発生しがちですが、AIであれば常に一定の精度で監視を続けられ、ヒューマンエラーの防止にもつながります。
AI導入におけるデメリットや注意点
AI導入におけるデメリットや注意点として以下の4点が挙げられます。
- 現場の正確なデータが記録・管理されていなければ機能しない
- 導入・運用コスト(初期費用、専門人材、データ収集・整備)
- 学習データの質と量が精度を左右する(特に異常データは少ない)
- AIに依存した現場体制は人材が育たない(AIが適切かどうか人間が判断ができなくなる)
現場の正確なデータが記録・管理されていなければ機能しない
AIは正常な状態のパターンをもとに異常を判定するため、作業者・設備・原料・作業方法といった4M(Man, Machine, Material, Method)のAIが想定していない変化に極めて弱い側面があります。
例えば、原料の性質や作業者の手順が少し変わるだけでもAIは「異常」と誤認識する恐れがあります。こうしたリスクを防ぐには、まず現場で正確なデータを継続的に記録・管理できるプラットフォームが必要です。
AIは正常時のパターンを学習して異常を判断するため、原料や作業方法の変化など予期しない4Mの変動に弱く、誤検知の原因になります。
そこで、1つの有効手段である「デジタル現場帳票(例:tebiki現場分析)」を使えば、こうした変化をリアルタイムに記録・可視化できます。そこで取った記録とセンサーデータを紐付けることで、AIの誤判定を極力抑え、より精度の高い異常検知が可能になります。
デジタル現場帳票の詳しい機能や、デジタル化するための推進方法については、以下のガイドブックで理解を深められます。あわせて参考にしてみてください(下の画像をクリック)。

導入・運用コスト(初期費用、専門人材、データ収集・整備)
AI異常検知システムの導入にセンサーの設置やネットワークの構築、AIモデルの設計・学習などにかかる初期費用が発生します。さらに、AIを活用するためには、機械学習やデータ解析に精通した人材の確保も必要です。
運用後も、システムのチューニングや再学習、データ更新といったメンテナンス業務が継続的に発生するため、コストは導入時だけでなく長期にわたって発生します。費用対効果を十分に見極めたうえで、計画的な導入が求められます。
学習データの質と量が精度を左右する(特に異常データは少ない)
AIモデルの性能は、学習に使われるデータの質と量に大きく影響します。正常データは比較的多く収集できますが、異常データは発生頻度が低く、種類も多様なため収集が困難です。
そのため、偏ったデータセットで学習させてしまうと、未知の異常を検知できないリスクが高まります。教師なし学習や生成モデルなどの技術を活用する手段もありますが、完全な精度を保証するものではありません。継続的なデータ収集とモデルの改善が必要です。
AIに依存した現場体制は人材が育たない(AIが適切かどうか人間が判断ができなくなる)
AIの導入が進むにつれ、現場での判断をAI任せにする傾向が強まると、人間側の判断力が低下してしまう懸念があります。AIが検知した内容が正しいのかを確認する力、あるいは異常を感知する人間の勘や経験は、AIでは完全に代替できません。
特に、AIの予測が不完全な場合や、想定外の事態が発生したときに、それに気づいて行動できる人材が不足すると、かえってリスクが高まります。AIと人の適切な役割分担が、今後の製造現場には求められます。
迅速かつ正確な異常検知を実施するには
迅速かつ正確な異常検知を実施するには、具体的に以下の3つの事項を意識しましょう。
- リアルタイムデータ取得の基盤構築こそが最重要
- 予知保全・予防保全との連携
- ヒューマンエラー対策と作業標準化
リアルタイムデータ取得の基盤構築こそが最重要
異常検知の精度の良し悪しを分ける最大の要因は、正確で即時性のあるデータの存在です。どれほど高度な分析手法やAIを導入しても、入力されるデータが不正確・不完全であれば、精度の高い異常検知は不可能です。
従来の工場では、紙やExcelによる記録が一般的でしたが、リアルタイム性に欠け、転記ミスや記録漏れが多く、データの集計・分析にも膨大な時間と手間がかかっていました。加えて、記録そのものが目的化し、現場の改善に活かされにくいという問題もあります。
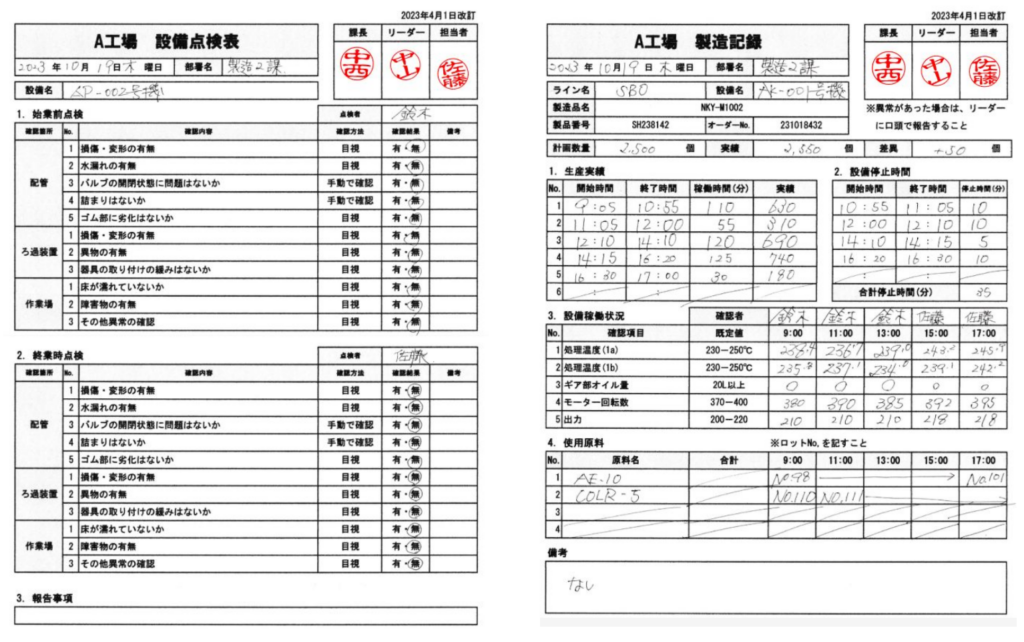
こうした課題を解決するのが「デジタル現場帳票」の導入です。タブレットなどを使った現場での直接入力により、リアルタイムでのデータ取得が可能になります。例えば、以下の紙の設備点検表は、製造業では見慣れている書類ですが、管理が煩雑で、記入ミスや入力ミスの原因になり、見返すことも難しいでしょう。
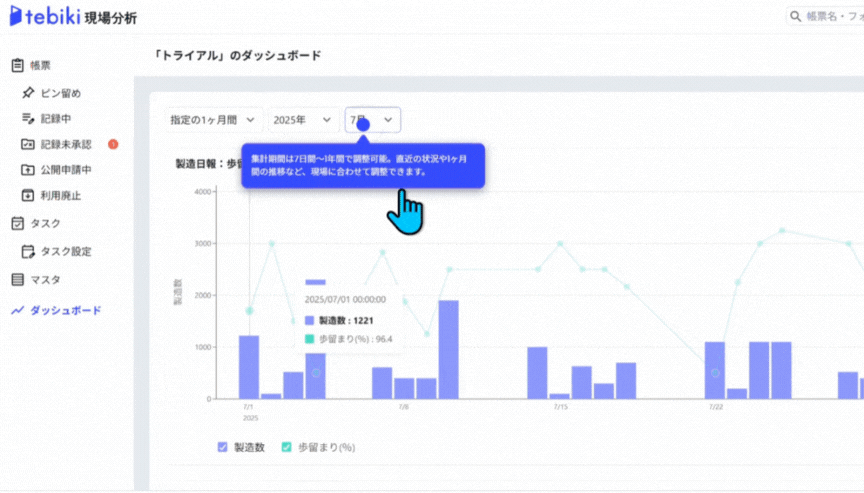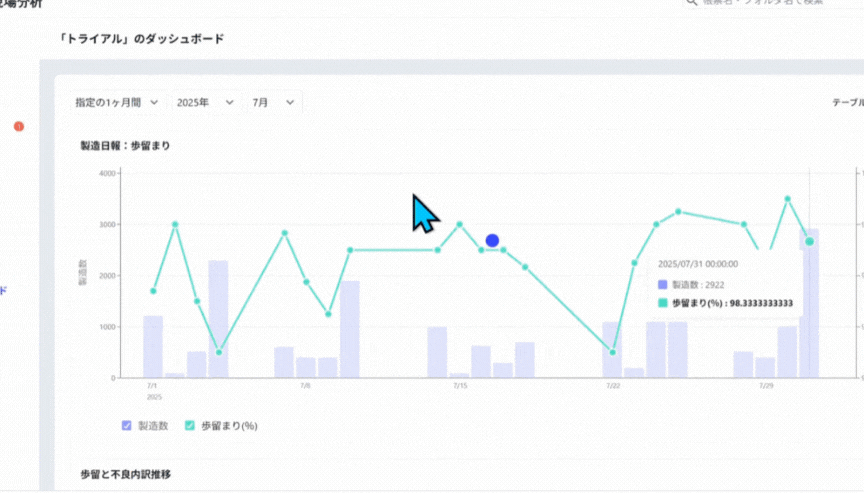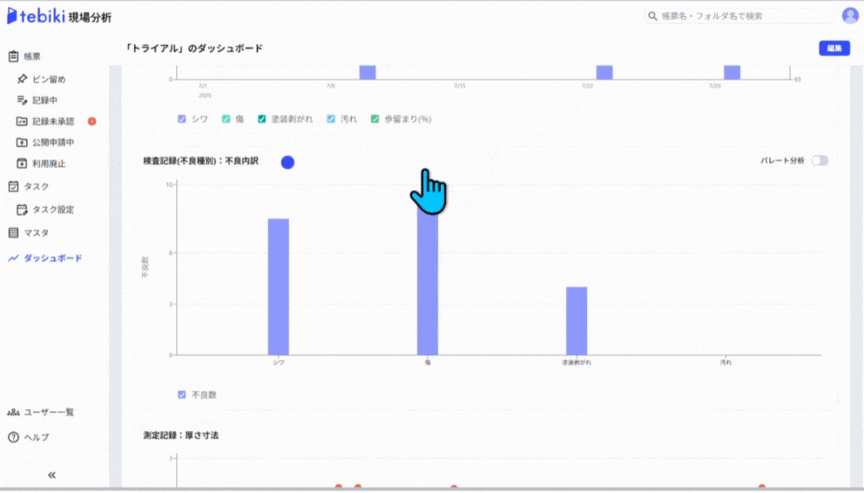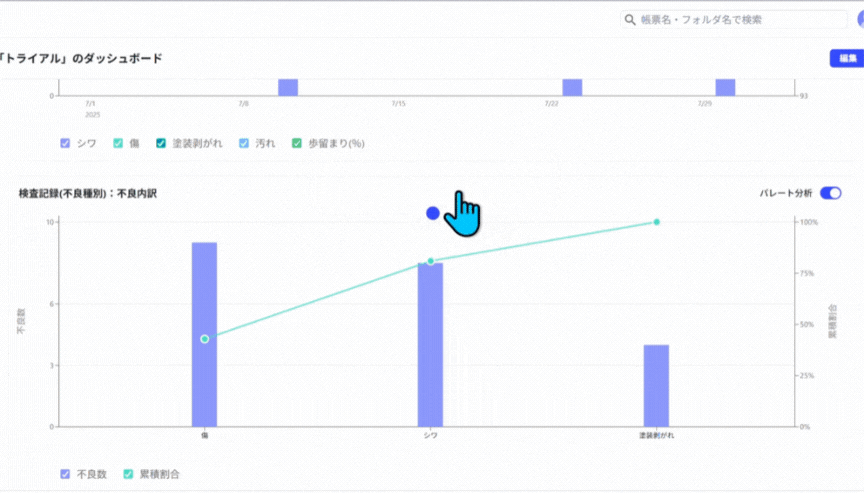
上の紙帳票をデジタル化すると、例えば以下のようなダッシュボードやグラフをPCやタブレット上で表示することが可能です。視覚的にも直感的にもわかりやすく、管理もしやすいデータとして保存できます。
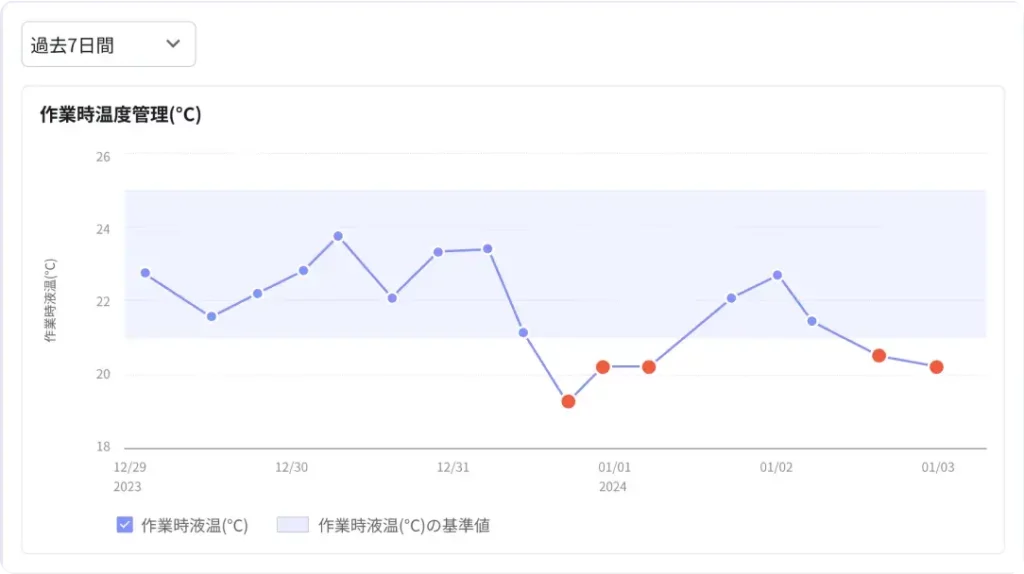
デジタル現場帳票「tebiki現場分析」のサンプルグラフから引用
こうしたグラフは、基本的に自動集計がなされるため、傾向分析や異常の早期発見にもつながります。検索性の高さも大きな利点で、過去のトラブル履歴の追跡や対策の精度向上も期待できます。
また、現場帳票をデジタル化すると入力ミスが減り、項目やフォーマットの統一によってデータの標準化にもつながります。
紙やExcelによる現場帳票の運用に課題を感じ、リアルタイムなデータ活用による異常検知体制の構築にご関心のある方は、かんたんデジタル現場帳票「tebiki現場分析」のサービス資料もあわせて参考にしてみてください。下のリンクからご覧いただけます。
>>>かんたんデジタル現場帳票「tebiki現場分析」のサービス資料を見てみる
予知保全・予防保全との連携
異常を検知することはゴールではなく、トラブルの未然防止につなげるための通過点に過ぎません。どれだけ早期に異常を察知できたとしても、その後の対処が適切でなければ意味をなしません。
特に、設備の老朽化や負荷の増大によって故障が予測される場面では、予知保全や予防保全の考え方と異常検知を連携させることが重要です。
予知保全は、設備の状態をモニタリングしながら劣化の兆候を読み取り、トラブルが起こる前にメンテナンスを行う手法です。一方で、予防保全は稼働時間や使用頻度にもとづき、あらかじめ決められたタイミングで保守作業を行う手法です。
どちらも異常検知と密接に関わっており、収集したデータを正しく分析し、必要なタイミングでの対応に繋げる仕組みが求められます。
AIによる異常検知は、従来見逃されていた微細な兆候を察知する点で有効です。その情報を予知保全・予防保全の計画にフィードバックすることで、設備停止のリスクを大幅に低減することが可能になります。
さらに、過去のトラブルデータと照らし合わせることで、メンテナンスの最適化や工数の削減も期待できます。
「製造業の設備トラブルによる生産性低下を解消する設備保全のDX(pdf)」では、保全業務を形式知化して設備の異常を早期発見する術がまとめられているので、あわせて参考にしてみてください(下の画像をクリック)。
ヒューマンエラー対策と作業標準化
異常の原因は設備や機械に限られるわけではありません。現場で多く発生するのが、作業者の判断ミスや手順ミスといったヒューマンエラーによる異常です。ヒューマンエラーを減らすには、作業の標準化と教育の徹底が欠かせません。
標準化とは、誰が作業しても同じ結果が得られるように、手順や方法を統一することです。作業内容を明文化し、教育・訓練を通じてそのルールを現場に浸透させることで、手順のばらつきや判断の迷いがなくなり、安定した品質と安全性が確保されます。
標準化は「現場教育」にかかっていますが、多くの製造現場では、標準化の浸透を目的とした教育体制を整備する時間がなかなか取れていません。
そこで、資料「新人教育に失敗する製造現場に潜む3つの構造的要因と新しい教育アプローチ(pdf)」では、教育が進まない現場の根本的な課題について解説しつつ、課題を解決するための現場教育の体制整備方法をまとめています。
下の画像をクリックすると資料をご覧いただけるので、あわせて参考にしてみてください。

異常検知に成功している製造業の事例
異常検知に成功している製造業の事例として以下の2社を紹介します。
- 株式会社日本電気化学工業所(NACL)
- 共栄工業株式会社
またAIを活用した異常検知の取り組み事例も紹介するので、ぜひ参考にしてみてください。
株式会社日本電気化学工業所(NACL):リアルタイムデータ管理による迅速な異常検知の体制を構築
株式会社日本電気化学工業所(NACL)は、製造現場の品質管理を強化するために、現場帳票をデジタル化し、リアルタイムデータの活用による異常検知体制の高度化を実現しました。
従来は紙ベースの帳票に依存していたため、異常値の検出に時間がかかり、迅速な対応が困難でした。また、記録が目的化し、収集したデータが改善活動に活かされていないこと、さらには承認プロセスに多くの工数がかかるなど、現場運用全体に非効率さが課題だったと言います。
しかし帳票電子化により、最大の変化はデータのリアルタイム監視が可能になったことです。特に印象的だったのは、温度データのわずかな変化をダッシュボードで検知し、配管に小さな穴が開いていたことを早期に発見できた点とのことでした。
▼同社の事例インタビュー動画▼
担当者は「もし従来の紙ベースの記録管理だったら、このような微細な変化を見逃してしまい、問題が大きくなってから気づいたかもしれません」と振り返っており、リアルタイム性の重要性を実感しています。
同社の事例は以下のリンクからも閲覧可能ですので、ぜひこの機会にチェックしてみてください。
インタビュー記事:品質不良の未然防止をリアルタイムデータで実現。異常値検知を迅速にできた理由。
共栄工業株式会社:デジタル現場帳票による設備トラブルの未然防止を実現
共栄工業株式会社では従来の紙帳票からExcelへの転記・集計に1日2時間以上を要し、記録したデータの分析が後回しになるなど、現場の効率と改善活動に大きな課題を抱えていました。また、現場の作業進捗を把握するには直接足を運ぶ必要があり、即時の判断や対応が難しい状況でした。
こうした課題を解消するため、同社は現場帳票を電子化しました。結果、転記・集計作業は1日2時間から約1分へと劇的に短縮され、週次・月次の集計も数時間から30分程度に削減されました。
さらに、記録データは即座にダッシュボードに反映され、例えば冬季の湯洗温度の立ち上がり遅延を早期に把握し、対応を前倒しするなどの改善活動につながっています。
また、設備トラブルの記録データから点検頻度を見直すなど、予防処置にも活用されています。リアルタイムに作業進捗を把握できることで、他部門との連携や1人作業時の安全確認も可能となり、全体の業務効率が向上。スマホに最適化された入力機能により、現場スタッフの作業負担も軽減されています。
同社の詳細な事例は以下のリンクから閲覧可能ですので、あわせてご覧ください。
インタビュー記事:1日2時間の集計作業が約1分に。スチール製家具製造の共栄工業のデジタル改革
AIを活用した異常検知の取り組み事例
株式会社Specteeは、日本気象協会およびNCTと連携し、新潟県長岡市においてAIによる道路の「路面状態判別技術」および「視程判別技術」の実証実験を開始しました。
実験では、NCTが設置した道路カメラの映像をAIがリアルタイムで解析し、凍結・積雪・シャーベット状などの路面状態や、吹雪による視界不良(ホワイトアウト含む)の程度を階級別に判別。結果として、従来の定点観測機器では難しかった広範囲かつ即時的な道路状況の把握が可能になりました。
AI技術を活用することで、道路管理者や自治体がタイムリーに安全対策を講じられ、災害対応や交通事故防止、自動運転技術の支援にもつながる取り組みとして注目されています。
参考記事:AIによる道路の「路面状態判別技術」の実証実験を新潟県長岡市にて開始(PR TIMES)
まとめ:工場における異常検知はデータ活用基盤の整備から
本記事では、工場における異常検知の基本からAIの活用事例までを解説してきました。
異常検知には多様な手法がありますが、どの手法も「高品質なデータを効率的かつリアルタイムに取得・管理できるか」が成否を分けます。
AIなどの高度な技術も、土台となるデータ基盤が不十分では真価を発揮できません。まずは現場帳票のデジタル化を導入することが有効です。
工場での効果的な異常検知体制の構築は、まず足元のデータ収集・管理の仕組みを見直すことから始まります。現場帳票のデジタル化に関心をお持ちの方は、まずこちらのガイドで基本から学んでみませんか。